Webmaster Level: Intermediate
Google uses numerous sources to find new webpages, from links we find on the web to submitted URLs. We aim to discover new pages quickly so that users can find new content in Google search results soon after they go live. We recently launched a feature that uses RSS and Atom feeds for the discovery of new webpages.
RSS/Atom feeds have been very popular in recent years as a mechanism for content publication. They allow readers to check for new content from publishers. Using feeds for discovery allows us to get these new pages into our index more quickly than traditional crawling methods. We may use many potential sources to access updates from feeds including Reader, notification services, or direct crawls of feeds. Going forward, we might also explore mechanisms such as PubSubHubbub to identify updated items.
In order for us to use your RSS/Atom feeds for discovery, it's important that crawling these files is not disallowed by your robots.txt. To find out if Googlebot can crawl your feeds and find your pages as fast as possible, test your feed URLs with the robots.txt tester in Google Webmaster Tools.
Kamis, 29 Oktober 2009
Senin, 26 Oktober 2009
Help us make the web better: An update on Rich Snippets
Webmaster Level: All
In May this year we announced Rich Snippets which makes it possible to show structured data from your pages on Google's search results.

We're convinced that structured data makes the web better, and we've worked hard to expand Rich Snippets to more search results and collect your feedback along the way. If you have review or people/social networking content on your site, it's easier than ever to mark up your content using microformats or RDFa so that Google can better understand it to generate useful Rich Snippets. Here are a few helpful improvements on our end to enable you to mark up your content:
Testing tool. See what Google is able to extract, and preview how microformats or RDFa marked-up pages would look on Google search results. Test your URLs on the Rich Snippets Testing Tool.

Google Custom Search users can also use the Rich Snippets Testing Tool to test markup usable in their Custom Search engine.
Better documentation. We've extended our documentation to include a new section containing Tips & Tricks and Frequently Asked Questions. Here we have responded to common points of confusion and provided instructions on how to maximize the chances of getting Rich Snippets for your site.
Extended RDFa support. In addition to the Person RDFa format, we have added support for the corresponding fields from the FOAF and vCard vocabularies for all those of you who asked for it.
Videos. If you have videos on your page, you can now mark up your content to help Google find those videos.
As before, marking up your content does not guarantee that Rich Snippets will be shown for your site. We will continue to expand this feature gradually to ensure a great user experience whenever Rich Snippets are shown in search results.
In May this year we announced Rich Snippets which makes it possible to show structured data from your pages on Google's search results.

We're convinced that structured data makes the web better, and we've worked hard to expand Rich Snippets to more search results and collect your feedback along the way. If you have review or people/social networking content on your site, it's easier than ever to mark up your content using microformats or RDFa so that Google can better understand it to generate useful Rich Snippets. Here are a few helpful improvements on our end to enable you to mark up your content:
Testing tool. See what Google is able to extract, and preview how microformats or RDFa marked-up pages would look on Google search results. Test your URLs on the Rich Snippets Testing Tool.

Google Custom Search users can also use the Rich Snippets Testing Tool to test markup usable in their Custom Search engine.
Better documentation. We've extended our documentation to include a new section containing Tips & Tricks and Frequently Asked Questions. Here we have responded to common points of confusion and provided instructions on how to maximize the chances of getting Rich Snippets for your site.
Extended RDFa support. In addition to the Person RDFa format, we have added support for the corresponding fields from the FOAF and vCard vocabularies for all those of you who asked for it.
Videos. If you have videos on your page, you can now mark up your content to help Google find those videos.
As before, marking up your content does not guarantee that Rich Snippets will be shown for your site. We will continue to expand this feature gradually to ensure a great user experience whenever Rich Snippets are shown in search results.
Kamis, 22 Oktober 2009
Verifying a Blogger blog in Webmaster Tools
Webmaster Level: All
You may have seen our recent announcement of changes to the verification system in Webmaster Tools. One side effect of this change is that blogs hosted on Blogger (that haven't yet been verified) will have to use the meta tag verification method rather than the "one-click" integration from the Blogger dashboard. The "Webmaster Tools" auto-verification link from the Blogger dashboard is no longer working and will soon be removed. We're working to reinstate an automated verification approach for Blogger hosted blogs in the future, but for the time being we wanted you to be aware of the steps required to verify your Blogger blog in Webmaster Tools.
Step-By-Step Instructions:
In Webmaster Tools
1. Click the "Add a site" button on the Webmaster Tools Home page
2. Enter your blog's URL (for example, googlewebmastercentral.blogspot.com) and click the "Continue" button to go to the Manage verification page
3. Select the "Meta tag" verification method and copy the meta tag provided
In Blogger
4. Go to your blog and sign in
5. From the Blogger dashboard click the "Layout" link for the blog you're verifying
6. Click the "Edit HTML" link under the "Layout" tab which will allow you to edit the HTML for your blog's template
7. Paste the meta tag (copied in step 3) immediately after the <head> element within the template HTML and click the "SAVE TEMPLATE" button
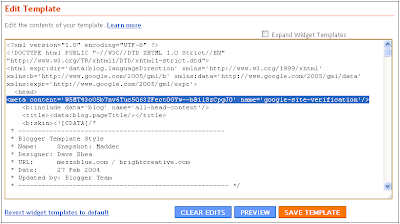
In Webmaster Tools
8. On the Manage Verification page, confirm that "Meta tag" is selected as the verification method and click the "Verify" button
Your blog should now be verified. You're ready to start using Webmaster Tools!
You may have seen our recent announcement of changes to the verification system in Webmaster Tools. One side effect of this change is that blogs hosted on Blogger (that haven't yet been verified) will have to use the meta tag verification method rather than the "one-click" integration from the Blogger dashboard. The "Webmaster Tools" auto-verification link from the Blogger dashboard is no longer working and will soon be removed. We're working to reinstate an automated verification approach for Blogger hosted blogs in the future, but for the time being we wanted you to be aware of the steps required to verify your Blogger blog in Webmaster Tools.
Step-By-Step Instructions:
In Webmaster Tools
1. Click the "Add a site" button on the Webmaster Tools Home page
2. Enter your blog's URL (for example, googlewebmastercentral.blogspot.com) and click the "Continue" button to go to the Manage verification page
3. Select the "Meta tag" verification method and copy the meta tag provided
In Blogger
4. Go to your blog and sign in
5. From the Blogger dashboard click the "Layout" link for the blog you're verifying
6. Click the "Edit HTML" link under the "Layout" tab which will allow you to edit the HTML for your blog's template
7. Paste the meta tag (copied in step 3) immediately after the <head> element within the template HTML and click the "SAVE TEMPLATE" button

In Webmaster Tools
8. On the Manage Verification page, confirm that "Meta tag" is selected as the verification method and click the "Verify" button
Your blog should now be verified. You're ready to start using Webmaster Tools!
Rabu, 21 Oktober 2009
One million YouTube views!
Earlier this year, we launched our very own Webmaster Central channel on YouTube. Just today, we saw our total video views exceed one million! On the road to this milestone, we uploaded 154 videos, for a total of nearly 11 hours of webmaster-focused media. These videos have brought you conference presentations, updates on tools for webmasters, general tips, and of course answers to your "Grab bag" questions for Matt Cutts.
To celebrate our one million views, we're sharing a fun video with you in which Matt Cutts shows us what happened when he lost a bet with his team:
We're also pleased to announce that we've added captions to all of our videos and plan to do so for our future videos as well. Thank you to everyone who has watched, shared, and commented on our videos. We look forward to the next million views!
To celebrate our one million views, we're sharing a fun video with you in which Matt Cutts shows us what happened when he lost a bet with his team:
We're also pleased to announce that we've added captions to all of our videos and plan to do so for our future videos as well. Thank you to everyone who has watched, shared, and commented on our videos. We look forward to the next million views!
Jumat, 16 Oktober 2009
Dealing with low-quality backlinks
Webmaster level: Intermediate/Advanced
Webmasters who check their incoming links in Webmaster Tools often ask us what they can do when they see low-quality links. Understandably, many site owners are trying to build a good reputation for their sites, and some believe that having poor-quality incoming links can be perceived as "being part of a bad neighbourhood," which over time might harm their site's ranking.

If your site receives links that look similarly dodgy, don't be alarmed... read on!
While it's true that linking is a significant factor in Google's ranking algorithms, it's just one of many. I know we say it a lot, but having something that people want to look at or use—unique, engaging content, or useful tools and services—is also a huge factor. Other factors can include how a site is structured, whether the words of a user's query appear in the title, how close the words are on the page, and so on. The point is, if you happen to see some low quality sites linking to you, it's important to keep in mind that linking is just one aspect among many of how Google judges your site. If you have a well-structured and regularly maintained site with original, high-quality content, those are the sorts of things that users will see and appreciate.
That having said, in an ideal world you could have your cake and eat it too (or rather, you could have a high-quality site and high-quality backlinks). You may also be concerned about users' perception of your site if they come across it via a batch of spammy links. If the number of poor-quality links is manageable, and/or if it looks easy to opt-out or get those links removed from the site that's linking to you, it may be worth it to try to contact the site(s) and ask them to remove their links. Remember that this isn't something that Google can do for you; we index content that we find online, but we don't control that content or who's linking to you.
If you run into some uncooperative site owners, however, don't fret for too long. Instead, focus on things that are under your control. Generally, you as a webmaster don't have much control over things like who links to your site. You do, however, have control over many other factors that influence indexing and ranking. Organize your content; do a mini-usability study with family or friends. Ask for a site review in your favorite webmaster forums. Use a website testing tool to figure out what gets you the most readers, or the biggest sales. Take inspiration from your favorite sites, or your competitors—what do they do well? What makes you want to keep coming back to their sites, or share them with your friends? What can you learn from them? Time spent on any of these activities is likely to have a larger impact on your site's overall performance than time spent trying to hunt down and remove every last questionable backlink.
Finally, keep in mind that low-quality links rarely stand the test of time, and may disappear from our link graph relatively quickly. They may even already be being discounted by our algorithms. If you want to make sure Google knows about these links and is valuing them appropriately, feel free to bring them to our attention using either our spam report or our paid links report.
Webmasters who check their incoming links in Webmaster Tools often ask us what they can do when they see low-quality links. Understandably, many site owners are trying to build a good reputation for their sites, and some believe that having poor-quality incoming links can be perceived as "being part of a bad neighbourhood," which over time might harm their site's ranking.

If your site receives links that look similarly dodgy, don't be alarmed... read on!
While it's true that linking is a significant factor in Google's ranking algorithms, it's just one of many. I know we say it a lot, but having something that people want to look at or use—unique, engaging content, or useful tools and services—is also a huge factor. Other factors can include how a site is structured, whether the words of a user's query appear in the title, how close the words are on the page, and so on. The point is, if you happen to see some low quality sites linking to you, it's important to keep in mind that linking is just one aspect among many of how Google judges your site. If you have a well-structured and regularly maintained site with original, high-quality content, those are the sorts of things that users will see and appreciate.
That having said, in an ideal world you could have your cake and eat it too (or rather, you could have a high-quality site and high-quality backlinks). You may also be concerned about users' perception of your site if they come across it via a batch of spammy links. If the number of poor-quality links is manageable, and/or if it looks easy to opt-out or get those links removed from the site that's linking to you, it may be worth it to try to contact the site(s) and ask them to remove their links. Remember that this isn't something that Google can do for you; we index content that we find online, but we don't control that content or who's linking to you.
If you run into some uncooperative site owners, however, don't fret for too long. Instead, focus on things that are under your control. Generally, you as a webmaster don't have much control over things like who links to your site. You do, however, have control over many other factors that influence indexing and ranking. Organize your content; do a mini-usability study with family or friends. Ask for a site review in your favorite webmaster forums. Use a website testing tool to figure out what gets you the most readers, or the biggest sales. Take inspiration from your favorite sites, or your competitors—what do they do well? What makes you want to keep coming back to their sites, or share them with your friends? What can you learn from them? Time spent on any of these activities is likely to have a larger impact on your site's overall performance than time spent trying to hunt down and remove every last questionable backlink.
Finally, keep in mind that low-quality links rarely stand the test of time, and may disappear from our link graph relatively quickly. They may even already be being discounted by our algorithms. If you want to make sure Google knows about these links and is valuing them appropriately, feel free to bring them to our attention using either our spam report or our paid links report.
Let's make the mobile web faster
(Cross-posted on the Google Code Blog)
This week, we've been celebrating all things mobile across Google. Of course, this wouldn't be complete without a component for mobile web developers! Two months ago we asked you to make the web faster. Now, we've asked the Google Mobile team for some best practices, tips, and resources for mobile web development, and we've come up with a few things we wanted to share. "Go Mobile!" with our Make the mobile web faster article.
This week, we've been celebrating all things mobile across Google. Of course, this wouldn't be complete without a component for mobile web developers! Two months ago we asked you to make the web faster. Now, we've asked the Google Mobile team for some best practices, tips, and resources for mobile web development, and we've come up with a few things we wanted to share. "Go Mobile!" with our Make the mobile web faster article.
Kamis, 15 Oktober 2009
Managing your reputation through search results
(Cross-posted on the Official Google Blog)
A few years ago I couldn't wait to get married. Because I was in love, yeah; but more importantly, so that I could take my husband's name and people would stop getting that ridiculous picture from college as a top result when they searched for me on Google.
After a few years of working here, though, I've learned that you don't have to change your name just because it brings up some embarrassing search results. Below are some tips for "reputation management": influencing how you're perceived online, and what information is available relating to you.
Think twice
The first step in reputation management is preemptive: Think twice before putting your personal information online. Remember that although something might be appropriate for the context in which you're publishing it, search engines can make it very easy to find that information later, out of context, including by people who don't normally visit the site where you originally posted it. Translation: don't assume that just because your mom doesn't read your blog, she'll never see that post about the new tattoo you're hiding from her.
Tackle it at the source
If something you dislike has already been published, the next step is to try to remove it from the site where it's appearing. Rather than immediately contacting Google, it's important to first remove it from the site where it's being published. Google doesn't own the Internet; our search results simply reflect what's already out there on the web. Whether or not the content appears in Google's search results, people are still going to be able to access it — on the original site, through other search engines, through social networking sites, etc. — if you don't remove it from the original site. You need to tackle this at the source.
Proactively publish information
Sometimes, however, you may not be able to get in touch with a site's webmaster, or they may refuse to take down the content in question. For example, if someone posts a negative review of your business on a restaurant review or consumer complaint site, that site might not be willing to remove the review. If you can't get the content removed from the original site, you probably won't be able to completely remove it from Google's search results, either. Instead, you can try to reduce its visibility in the search results by proactively publishing useful, positive information about yourself or your business. If you can get stuff that you want people to see to outperform the stuff you don't want them to see, you'll be able to reduce the amount of harm that that negative or embarrassing content can do to your reputation.
You can publish or encourage positive content in a variety of ways:
A few years ago I couldn't wait to get married. Because I was in love, yeah; but more importantly, so that I could take my husband's name and people would stop getting that ridiculous picture from college as a top result when they searched for me on Google.
After a few years of working here, though, I've learned that you don't have to change your name just because it brings up some embarrassing search results. Below are some tips for "reputation management": influencing how you're perceived online, and what information is available relating to you.
Think twice
The first step in reputation management is preemptive: Think twice before putting your personal information online. Remember that although something might be appropriate for the context in which you're publishing it, search engines can make it very easy to find that information later, out of context, including by people who don't normally visit the site where you originally posted it. Translation: don't assume that just because your mom doesn't read your blog, she'll never see that post about the new tattoo you're hiding from her.
Tackle it at the source
If something you dislike has already been published, the next step is to try to remove it from the site where it's appearing. Rather than immediately contacting Google, it's important to first remove it from the site where it's being published. Google doesn't own the Internet; our search results simply reflect what's already out there on the web. Whether or not the content appears in Google's search results, people are still going to be able to access it — on the original site, through other search engines, through social networking sites, etc. — if you don't remove it from the original site. You need to tackle this at the source.
- If the content in question is on a site you own, easy — just remove it. It will naturally drop out of search results after we recrawl the page and discover the change.
- It's also often easy to remove content from sites you don't own if you put it there, such as photos you've uploaded, or content on your profile page.
- If you can't remove something yourself, you can contact the site's webmaster and ask them to remove the content or the page in question.
Proactively publish information
Sometimes, however, you may not be able to get in touch with a site's webmaster, or they may refuse to take down the content in question. For example, if someone posts a negative review of your business on a restaurant review or consumer complaint site, that site might not be willing to remove the review. If you can't get the content removed from the original site, you probably won't be able to completely remove it from Google's search results, either. Instead, you can try to reduce its visibility in the search results by proactively publishing useful, positive information about yourself or your business. If you can get stuff that you want people to see to outperform the stuff you don't want them to see, you'll be able to reduce the amount of harm that that negative or embarrassing content can do to your reputation.
You can publish or encourage positive content in a variety of ways:
- Create a Google profile. When people search for your name, Google can display a link to your Google profile in our search results and people can click through to see whatever information you choose to publish in your profile.
- If a customer writes a negative review of your business, you could ask some of your other customers who are happy with your company to give a fuller picture of your business.
- If a blogger is publishing unflattering photos of you, take some pictures you prefer and publish them in a blog post or two.
- If a newspaper wrote an article about a court case that put you in a negative light, but which was subsequently ruled in your favor, you can ask them to update the article or publish a follow-up article about your exoneration. (This last one may seem far-fetched, but believe it or not, we've gotten multiple requests from people in this situation.)
Senin, 12 Oktober 2009
Fetch as Googlebot and Malware details -- now in Webmaster Tools Labs!
The Webmaster Tools team is lucky to have passionate users who provide us with a great set of feature ideas. Going forward, we'll be launching some features under the "Labs" label so we can quickly transition from concept to production, and hear your feedback ASAP. With Labs releases, you have the opportunity to play with features and have your feedback heard much earlier in the development lifecycle. On the flip side, since these features are available early in the release cycle they're not as robust, and may break at times.
Before today, you may have been relying on manual testing, our safe browsing API, and malware notifications to determine which pages on your site may be distributing malware. Sometimes finding the malicious code is extremely difficult, even when you do know which pages it was found on. Today we are happy to announce that we'll be providing snippets of code that exist on some of those pages that we consider to be malicious. We hope this additional information enables you to eliminate the malware on your site very quickly, and reduces the number of iterations many webmasters go through during the review process.


Today we're launching two cool features:
- Malware details
- Fetch as Googlebot
Malware details (developed by Lucas Ballard)
More information on this cool feature is available at our Online Security Blog.

Fetch as Googlebot (developed by Javier Tordable)
"What does Googlebot see when it accesses my page?" is a common question webmasters ask us on our forums and at conferences. Our keywords and HTML suggestions features help you understand the content we're extracting from your site, and any issues we may be running into at crawl and indexing time. However, we realized it was important to provide the ability for users to submit pages on their site and get real-time feedback on what Googlebot sees. This feature will help users a great deal when they re-implement their site with a new technology stack, find out that some of their pages have been hacked, or want to understand why they're not ranking for specific keywords.

Rabu, 07 Oktober 2009
A proposal for making AJAX crawlable
Webmaster level: Advanced
Today we're excited to propose a new standard for making AJAX-based websites crawlable. This will benefit webmasters and users by making content from rich and interactive AJAX-based websites universally accessible through search results on any search engine that chooses to take part. We believe that making this content available for crawling and indexing could significantly improve the web.
While AJAX-based websites are popular with users, search engines traditionally are not able to access any of the content on them. The last time we checked, almost 70% of the websites we know about use JavaScript in some form or another. Of course, most of that JavaScript is not AJAX, but the better that search engines could crawl and index AJAX, the more that developers could add richer features to their websites and still show up in search engines.
Some of the goals that we wanted to achieve with this proposal were:
Here's how search engines would crawl and index AJAX in our initial proposal:
(Graphic by Katharina Probst)
In summary, starting with a stateful URL such as
http://example.com/dictionary.html#AJAX , it could be available to both crawlers and users as
http://example.com/dictionary.html#!AJAX which could be crawled as
http://example.com/dictionary.html?_escaped_fragment_=AJAX which in turn would be shown to users and accessed as
http://example.com/dictionary.html#!AJAX
View the presentation
We're currently working on a proposal and a prototype implementation. Feedback is very welcome — please add your comments below or in our Webmaster Help Forum. Thank you for your interest in making the AJAX-based web accessible and useful through search engines!
Today we're excited to propose a new standard for making AJAX-based websites crawlable. This will benefit webmasters and users by making content from rich and interactive AJAX-based websites universally accessible through search results on any search engine that chooses to take part. We believe that making this content available for crawling and indexing could significantly improve the web.
While AJAX-based websites are popular with users, search engines traditionally are not able to access any of the content on them. The last time we checked, almost 70% of the websites we know about use JavaScript in some form or another. Of course, most of that JavaScript is not AJAX, but the better that search engines could crawl and index AJAX, the more that developers could add richer features to their websites and still show up in search engines.
Some of the goals that we wanted to achieve with this proposal were:
- Minimal changes are required as the website grows
- Users and search engines see the same content (no cloaking)
- Search engines can send users directly to the AJAX URL (not to a static copy)
- Site owners have a way of verifying that their AJAX website is rendered correctly and thus that the crawler has access to all the content
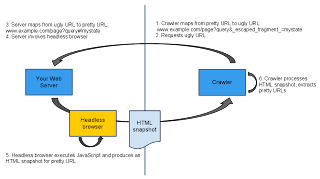
Here's how search engines would crawl and index AJAX in our initial proposal:
- Slightly modify the URL fragments for stateful AJAX pages
Stateful AJAX pages display the same content whenever accessed directly. These are pages that could be referred to in search results. Instead of a URL like http://example.com/page?query#state we would like to propose adding a token to make it possible to recognize these URLs: http://example.com/page?query#[FRAGMENTTOKEN]state . Based on a review of current URLs on the web, we propose using "!" (an exclamation point) as the token for this. The proposed URL that could be shown in search results would then be: http://example.com/page?query#!state. - Use a headless browser that outputs an HTML snapshot on your web server
The headless browser is used to access the AJAX page and generates HTML code based on the final state in the browser. Only specially tagged URLs are passed to the headless browser for processing. By doing this on the server side, the website owner is in control of the HTML code that is generated and can easily verify that all JavaScript is executed correctly. An example of such a browser is HtmlUnit, an open-sourced "GUI-less browser for Java programs. - Allow search engine crawlers to access these URLs by escaping the state
As URL fragments are never sent with requests to servers, it's necessary to slightly modify the URL used to access the page. At the same time, this tells the server to use the headless browser to generate HTML code instead of returning a page with JavaScript. Other, existing URLs - such as those used by the user - would be processed normally, bypassing the headless browser. We propose escaping the state information and adding it to the query parameters with a token. Using the previous example, one such URL would be http://example.com/page?query&[QUERYTOKEN]=state . Based on our analysis of current URLs on the web, we propose using "_escaped_fragment_" as the token. The proposed URL would then become http://example.com/page?query&_escaped_fragment_=state . - Show the original URL to users in the search results
To improve the user experience, it makes sense to refer users directly to the AJAX-based pages. This can be achieved by showing the original URL (such as http://example.com/page?query#!state from our example above) in the search results. Search engines can check that the indexable text returned to Googlebot is the same or a subset of the text that is returned to users.

(Graphic by Katharina Probst)
In summary, starting with a stateful URL such as
http://example.com/dictionary.html#AJAX , it could be available to both crawlers and users as
http://example.com/dictionary.html#!AJAX which could be crawled as
http://example.com/dictionary.html?_escaped_fragment_=AJAX which in turn would be shown to users and accessed as
http://example.com/dictionary.html#!AJAX
View the presentation
We're currently working on a proposal and a prototype implementation. Feedback is very welcome — please add your comments below or in our Webmaster Help Forum. Thank you for your interest in making the AJAX-based web accessible and useful through search engines!
Selasa, 06 Oktober 2009
Reunifying duplicate content on your website
Handling duplicate content within your own website can be a big challenge. Websites grow; features get added, changed and removed; content comes—content goes. Over time, many websites collect systematic cruft in the form of multiple URLs that return the same contents. Having duplicate content on your website is generally not problematic, though it can make it harder for search engines to crawl and index the content. Also, PageRank and similar information found via incoming links can get diffused across pages we aren't currently recognizing as duplicates, potentially making your preferred version of the page rank lower in Google.
Steps for dealing with duplicate content within your website
What about the robots.txt file?
One item which is missing from this list is disallowing crawling of duplicate content with your robots.txt file. We now recommend not blocking access to duplicate content on your website, whether with a robots.txt file or other methods. Instead, use the rel="canonical" link element, the URL parameter handling tool, or 301 redirects. If access to duplicate content is entirely blocked, search engines effectively have to treat those URLs as separate, unique pages since they cannot know that they're actually just different URLs for the same content. A better solution is to allow them to be crawled, but clearly mark them as duplicate using one of our recommended methods. If you allow us to crawl these URLs, Googlebot will learn rules to identify duplicates just by looking at the URL and should largely avoid unnecessary recrawls in any case. In cases where duplicate content still leads to us crawling too much of your website, you can also adjust the crawl rate setting in Webmaster Tools.
We hope these methods will help you to master the duplicate content on your website! Information about duplicate content in general can also be found in our Help Center. Should you have any questions, feel free to join the discussion in our Webmaster Help Forum.
Steps for dealing with duplicate content within your website
- Recognize duplicate content on your website.
The first and most important step is to recognize duplicate content on your website. A simple way to do this is to take a unique text snippet from a page and to search for it, limiting the results to pages from your own website by using a site:query in Google. Multiple results for the same content show duplication you can investigate. - Determine your preferred URLs.
Before fixing duplicate content issues, you'll have to determine your preferred URL structure. Which URL would you prefer to use for that piece of content? - Be consistent within your website.
Once you've chosen your preferred URLs, make sure to use them in all possible locations within your website (including in your Sitemap file). - Apply 301 permanent redirects where necessary and possible.
If you can, redirect duplicate URLs to your preferred URLs using a 301 response code. This helps users and search engines find your preferred URLs should they visit the duplicate URLs. If your site is available on several domain names, pick one and use the 301 redirect appropriately from the others, making sure to forward to the right specific page, not just the root of the domain. If you support both www and non-www host names, pick one, use the preferred domain setting in Webmaster Tools, and redirect appropriately. - Implement the rel="canonical" link element on your pages where you can.
Where 301 redirects are not possible, the rel="canonical" link element can give us a better understanding of your site and of your preferred URLs. The use of this link element is also supported by major search engines such as Ask.com, Bing and Yahoo!. - Use the URL parameter handling tool in Google Webmaster Tools where possible.
If some or all of your website's duplicate content comes from URLs with query parameters, this tool can help you to notify us of important and irrelevant parameters within your URLs. More information about this tool can be found in our announcement blog post.
What about the robots.txt file?
One item which is missing from this list is disallowing crawling of duplicate content with your robots.txt file. We now recommend not blocking access to duplicate content on your website, whether with a robots.txt file or other methods. Instead, use the rel="canonical" link element, the URL parameter handling tool, or 301 redirects. If access to duplicate content is entirely blocked, search engines effectively have to treat those URLs as separate, unique pages since they cannot know that they're actually just different URLs for the same content. A better solution is to allow them to be crawled, but clearly mark them as duplicate using one of our recommended methods. If you allow us to crawl these URLs, Googlebot will learn rules to identify duplicates just by looking at the URL and should largely avoid unnecessary recrawls in any case. In cases where duplicate content still leads to us crawling too much of your website, you can also adjust the crawl rate setting in Webmaster Tools.
We hope these methods will help you to master the duplicate content on your website! Information about duplicate content in general can also be found in our Help Center. Should you have any questions, feel free to join the discussion in our Webmaster Help Forum.
Senin, 05 Oktober 2009
New parameter handling tool helps with duplicate content issues
Duplicate content has been a hot topic among webmasters and our blog for over three years. One of our first posts on the subject came out in December of '06, and our most recent post was last week. Over the past three years, we've been providing tools and tips to help webmasters control which URLs we crawl and index, including a) use of 301 redirects, b) www vs. non-www preferred domain setting, c) change of address option, and d) rel="canonical".
We're happy to announce another feature to assist with managing duplicate content: parameter handling. Parameter handling allows you to view which parameters Google believes should be ignored or not ignored at crawl time, and to overwrite our suggestions if necessary.

Let's take our old example of a site selling Swedish fish. Imagine that your preferred version of the URL and its content looks like this:
{kind=link}
http://www.example.com/product.php?item=swedish-fish
However, you may also serve the same content on different URLs depending on how the user navigates around your site, or your content management system may embed parameters such as sessionid:
http://www.example.com/product.php?item=swedish-fish&category=gummy-candy
http://www.example.com/product.php?item=swedish-fish&trackingid=1234&sessionid=5678
With the "Parameter Handling" setting, you can now provide suggestions to our crawler to ignore the parameters category, trackingid, and sessionid. If we take your suggestion into account, the net result will be a more efficient crawl of your site, and fewer duplicate URLs.
Since we launched the feature, here are some popular questions that have come up:
Are the suggestions provided a hint or a directive?
Your suggestions are considered hints. We'll do our best to take them into account; however, there may be cases when the provided suggestions may do more harm than good for a site.
When do I use parameter handling vs rel="canonical"?
rel="canonical" is a great tool to manage duplicate content issues, and has had huge adoption. The differences between the two options are:
- rel="canonical" has to be put on each page, whereas parameter handling is set at the host level
- rel="canonical" is respected by many search engines, whereas parameter handling suggestions are only provided to Google
Use which option works best for you; it's fine to use both if you want to be very thorough.
As always, your feedback on our new feature is appreciated.
Jumat, 02 Oktober 2009
Google Friend Connect: No more FTP... just get started!
Update: The described product or service is no longer available.
Until today, you had to upload a file to your website to activate Google Friend Connect features and gadgets. Today, we're dramatically simplifying the Friend Connect setup process. To get started with Friend Connect features, all you have to do is submit your website's name and URL after logging into www.google.com/friendconnect.
To learn more about the recent updates to Google Friend Connect, check out our post on the Google Social Web Blog.
Kamis, 01 Oktober 2009
Changes to website verification in Webmaster Tools
If you use Webmaster Tools, you're probably familiar with verifying ownership of your sites. Simply add a specific meta tag or file to your site, click a button, and you're a verified owner. We've recently made a few small improvements to the process that we think will make it easier and more reliable for you.
The first change is an improvement to the meta tag verification method. In the past, your verification meta tag was partially based on the email address of your Google Account. That meant that if you changed the email address in your account settings, your meta tags would also change (and you'd become unverified for any sites you had used the old tag on). We've created a new version of the verification meta tag which is unrelated to your email address. Once you verify with a new meta tag, you'll never become unverified by changing your email address.
We've also revamped the way we do verification by HTML file. Previously, if your website returned an HTTP status code other than 404 for non-existent URLs, you would be unable to use the file verification method. A properly configured web server will return 404 for non-existent URLs, but it turns out that a lot of sites have problems with this requirement. We've simplified the file verification process to eliminate the checks for non-existent URLs. Now, you just download the HTML file we provide and upload it to your site without modification. We'll check the contents of the file, and if they're correct, you're done.
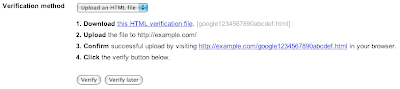
We hope these changes will make verification a little bit more pleasant. If you've already verified using the old methods, don't worry! Your existing verifications will continue to work. These changes only affect new verifications.
Some websites and software have features that help you verify ownership by adding the meta tag or file for you. They may need to be updated to work with the new methods. For example, Google Sites doesn't currently handle the new meta tag verification method correctly. We're aware of that problem and are working to fix it as soon as we can. If you discover other services that have similar problems, please work with their maintainer to resolve the issue. We're sorry if this causes any inconvenience.
This is just the first of several improvements we're working on for website verification. To give you a heads up, in a future update, we'll begin showing the email addresses of all verified owners of a given site to the other verified owners of that site. We think this will make it much easier to manage sites with multiple verified owners. However, if you're using an email address you wouldn't want the other owners of your site to see, now might be a good time to change it!
The first change is an improvement to the meta tag verification method. In the past, your verification meta tag was partially based on the email address of your Google Account. That meant that if you changed the email address in your account settings, your meta tags would also change (and you'd become unverified for any sites you had used the old tag on). We've created a new version of the verification meta tag which is unrelated to your email address. Once you verify with a new meta tag, you'll never become unverified by changing your email address.
We've also revamped the way we do verification by HTML file. Previously, if your website returned an HTTP status code other than 404 for non-existent URLs, you would be unable to use the file verification method. A properly configured web server will return 404 for non-existent URLs, but it turns out that a lot of sites have problems with this requirement. We've simplified the file verification process to eliminate the checks for non-existent URLs. Now, you just download the HTML file we provide and upload it to your site without modification. We'll check the contents of the file, and if they're correct, you're done.

We hope these changes will make verification a little bit more pleasant. If you've already verified using the old methods, don't worry! Your existing verifications will continue to work. These changes only affect new verifications.
Some websites and software have features that help you verify ownership by adding the meta tag or file for you. They may need to be updated to work with the new methods. For example, Google Sites doesn't currently handle the new meta tag verification method correctly. We're aware of that problem and are working to fix it as soon as we can. If you discover other services that have similar problems, please work with their maintainer to resolve the issue. We're sorry if this causes any inconvenience.
This is just the first of several improvements we're working on for website verification. To give you a heads up, in a future update, we'll begin showing the email addresses of all verified owners of a given site to the other verified owners of that site. We think this will make it much easier to manage sites with multiple verified owners. However, if you're using an email address you wouldn't want the other owners of your site to see, now might be a good time to change it!
Langganan:
Postingan (Atom)